文字コードって、とっても難しいです。
そんな文字コードの中で、文字符号化方式について、可能な限りわかりやすく解説します。
1.UTF-16 と UTF-32
ISO-2022-JP や EUC-JP 、Shift-JIS は、複数の文字集合を利用するための文字符号化方式です。
それに対して、UTF-16 や UTF-32、UTF-8 といった文字符号化方式は、使用している文字集合は Unicode のみです。
それなら Unicode を直接利用すれば良いのでは?と普通の人は思います。
そして実際に最初は Unicode を直接利用していました。Java や C# などは今は UTF-16 を利用していると言われていますが、当初は UTF-16 というより Unicode を利用していました。
当時の Unicode は、2 バイトの固定長でした。
2 バイトの固定長だと収録できる文字数は、256 × 256 = 65,536 で、世界中の文字を収録するには全然足りませんでした。
そこで 4 バイトに拡張した UTF-32 が登場し、それまでの Unicode は UTF-16 と呼ばれるようになりました。そして新しい Unicode は 8 〜 21 ビットの可変長となり、直接利用されることがなくなりました。
そのため UTF-16 を利用している大部分のソフトウェアは、当初は Unicode を利用していたのです。
このように Unicode、UTF16、UTF-32 は固定長か可変長の違いはありますが、基本的には同じコードになります。ただし UTF-16 は 65,536 を超える文字を表現するために、サロゲートペアと呼ばれる 2 文字分のコードで 1 文字を表す手法を使っていますので、UTF-16 のサロゲートペアは、文字コードが異なります。

2.リトルエンディアンとビッグエンディアン
UTF-16 と UTF-32 で少し厄介なのが、リトルエンディアン( LE )とビッグエンディアン( BE )です。
2 バイト文字の 1 桁目から格納する方式をビッグエンディアン、2 桁目から格納する方式をリトルエンディアンと呼びます。

これはデータをアドレス空間に格納する際、CPU によってデータの先頭から格納していく方式( BE )とデータの最後尾から格納していく方式( LE )が存在することに影響を受けています。
インテル系の CPU は LE を採用しています。プロトコルだと TCP/IP は BE 、USB は LE を採用していたり、JVMはBEを採用していたり、バラバラです。
このエンディアンが一致していると処理効率が良いのですが、逆になると少し処理効率が落ちます。
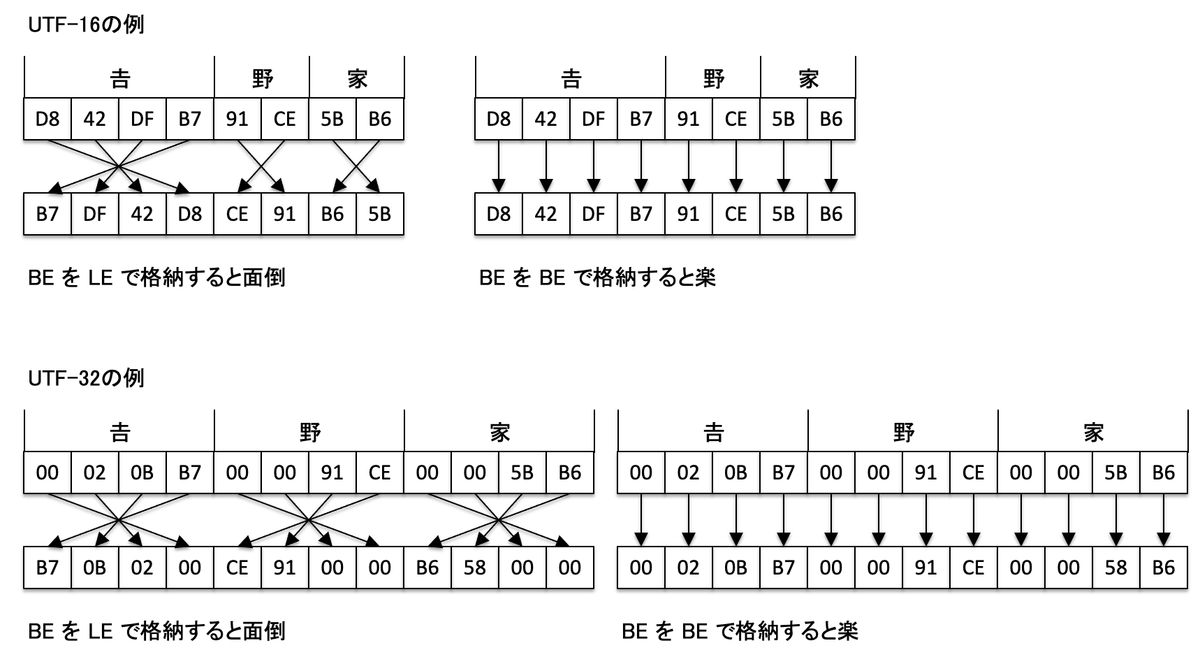
このエンディアンの考え方は、EUC-JP や ISO-2022-JP、Shift-JIS にはありません。
これらは「半角」文字は 1 バイトで、「全角」文字は 2 バイトですが、UTF-16(当時のUnicode)は全て 2 バイトです。
当時はコンピューターの処理能力が今ほど大きくなく、この文字のデータサイズの差を少しでも埋めるために、CPU やソフトウェアの処理効率が少しでも上がるようにエディアンの考え方を取り入れました。
さらにこのエンディアンには、BOM(Byte Order Mark)と呼ばれるコードがあります。
BOM を文字列の先頭につけることで、その文字列が BE なのか LE なのかを区別することができるようになります。
BE の BOM は FE FF で、LE の BOM は FF FE となります。
BOMをつけない場合には、文字符号化方式自体でBEかLEを宣言することになります。
つまり同じ UTF-16 でも、UTF-16 BE、UTF-16 LE、UTF-16 の3種類があり、さらにデータの並び順の違いも入れると、UTF-16 BE、UTF-16 LE、UTF-16( BE の BOM 付)、UTF-16( LE の BOM 付)、UTF-16( BOM なし)の5種類になります。

UTF-16( BOM なし)は、BE として扱われることが多いようです。
3.UTF-8
UTF-16 にはサロゲートペアの問題があり、UTF-32 は先頭 2 バイトの大部分が 0000 でメモリー利用効率が悪く、どっちもいまいちです。
そこで登場したのが UTF-8 です。
UTF-8 は可変長のため、固定長の文字コードよりも扱いにくいですが、コンピューターの処理性能が上がったことと、ASCⅡ と互換があることから、今や大部分のソフトウェアでは UTF-8 が使われるようになってきました。
UTF-8 は、UTF-16 や UTF-32 と違い、Unicode とは似ても似つかないコードになります。

UTF-8 の符号化方式は、以下のルールに従います。

このルールに従って Unicode を UTF-8 に変換すると以下のようになります。

U+0031 は、UTF-16 は「00 31」、UTF-32 は「00 00 00 31」です。それに対してUTF-8 は「31」で、ASCⅡ と全く同じなので重宝されているようです。
ただ漢字は 3 バイトや 4 バイトとなり、EUC-JP や ISO-2022-JP、Shift-JIS といった符号化方式よりもサイズが増えるため、一長一短なところはあります。

この UTF-8 にも BOM があります。
UTF-8 の BOM は「EF BB BF」です。本当は 2 バイトコードではない UTF-8 には BOM は必要ないのですが、UTF-8 であることを示すために付加されることがあります。
例えば WindowsPC で CSV ファイルをダブルクリックすると、Excel でファイルが開かれますが、このとき Excel は CSV の文字コードを CP932 として扱います。もし CSV の文字コードを UTF-8 で作成していると、CP932 として扱われるので文字化けします。
このとき、CSV を BOM 付きの UTF-8 で作成すると、Excel は正しく UTF-8 として扱ってくれるので文字化けしません。
ただし UTF-8 の BOM に対応していないソフトウェアもあるので、その場合には「EF BB BF」も文字として扱ってしまい、文字化けの原因となるので注意が必要です。
4.まとめ
符号化文字集合と文字符号化方式の説明は以上となります。
これらを図にすると以下のようになります。ちょっとごちゃごちゃして見にくいですが・・・。

以下は、文字コードのサンプルです。
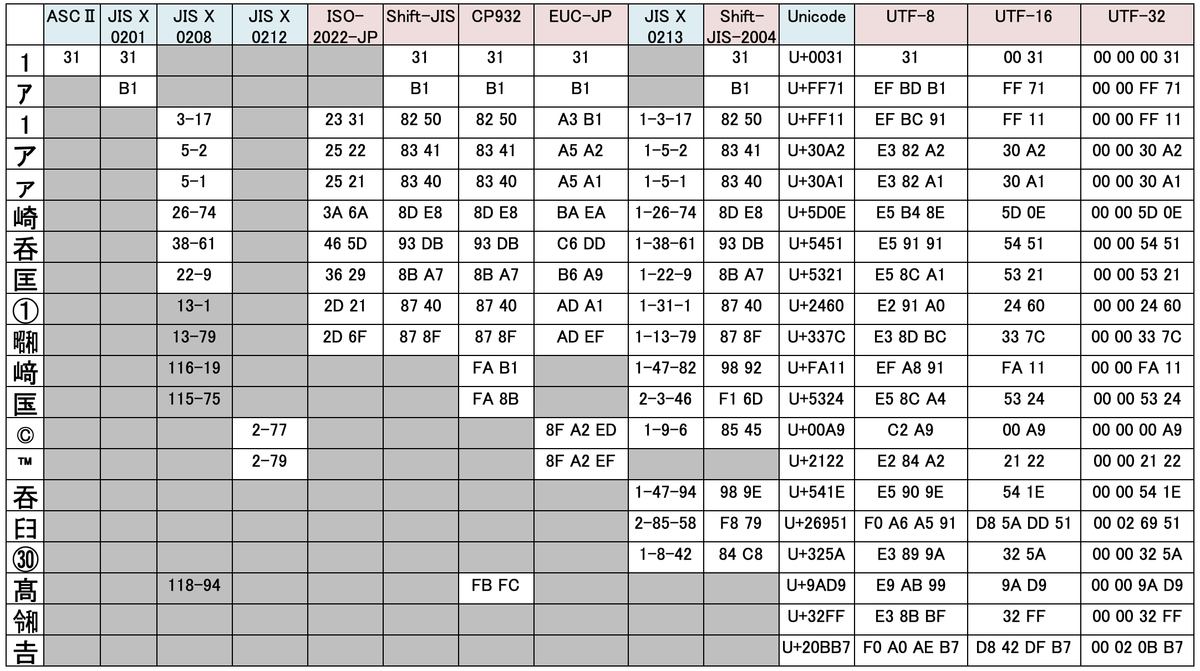
どの文字コードも ASCⅡ との互換を大切にしていることがわかります。
【振り返り】
第四回は、文字符号化方式(後編)でした。第五回は、サロゲートペアです。
第一回:概要
第二回:符号化文字集合
第三回:文字符号化方式(前編)
第四回:文字符号化方式(後編)
第五回:サロゲートペア
第六回:IVS
第七回:文字コードの歴史
第八回:文字化け