文字コードって、とっても難しいです。
そんな文字コードの中で、符号化文字集合について、可能な限りわかりやすく解説します。
1.符号化文字集合とは
「符号化文字集合」は、言葉どおり文字の集合です。ASCⅡやUnicode、JIS2004(JIS X 0213)などがこれにあたります。キャラクタセットとも呼びます。
例えば「1」という文字は、ASCⅡでは「31」、Unicodeでは「U+0031」になり、JIS2004には存在しません。「あ」という文字は、Unicodeでは「U+3042」、JIS2004では「2422」になり、ASCⅡには存在しません。
ASCⅡには制御コードを除いて 94 文字が収録されています。JIS2004には 11,234 文字、Unicodeには 143,859 文字(2020年3月の13.0.0バージョンの場合)が収録されています。
2.ASCⅡ
最初に作られた文字コードは、ASCⅡ(American Standard Code for Information Interchange)です。
1960年代に米国規格協会(ANSI)で定められました。ASCⅡは 7 ビットのコードで、2の 7 乗= 128 文字を表現できます。
そのうちの 34 文字は制御コードのため、実際に利用できる文字は 94 文字になります。この 94 という数字は、この後もたびたび登場します。
以下はASCⅡの文字コード表です。
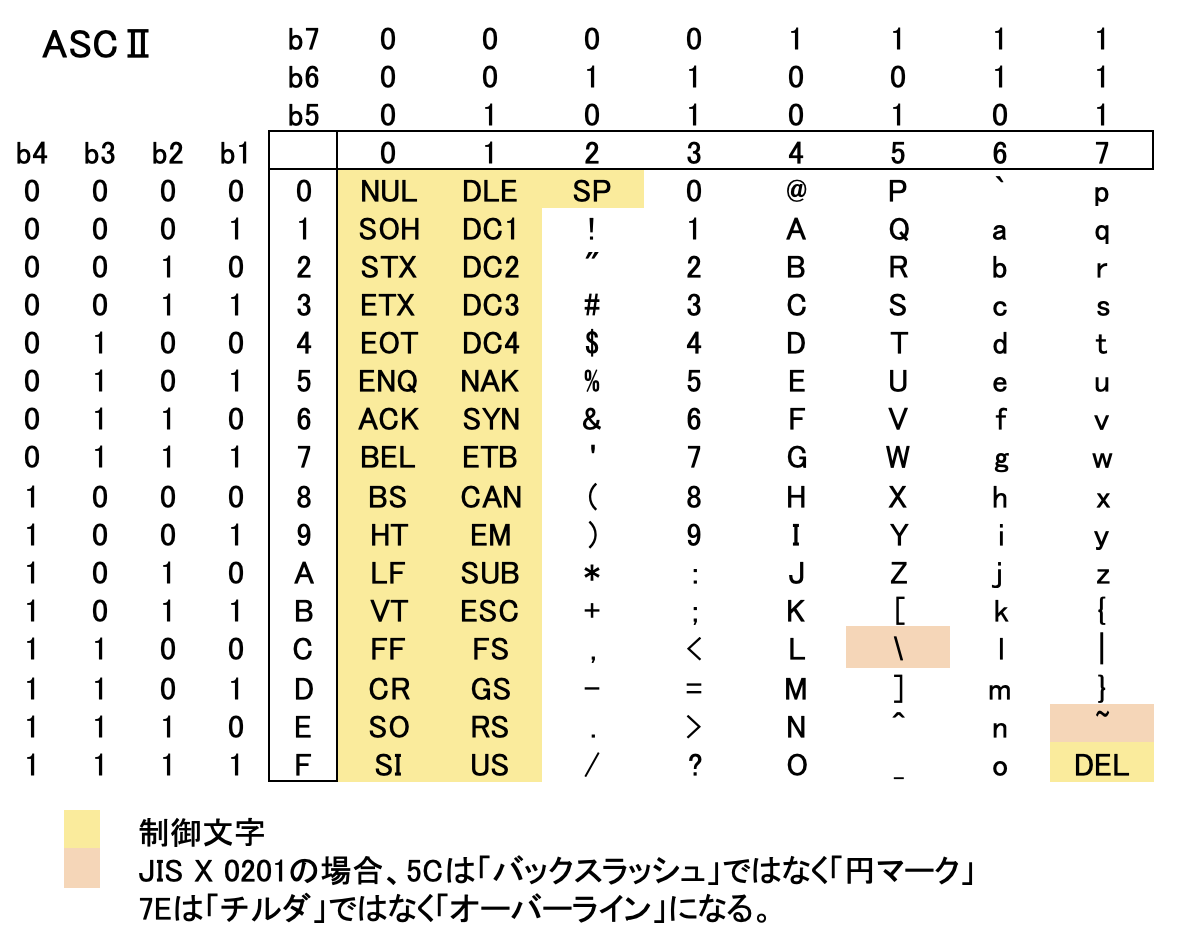
例えば「1」は16進表記で「31」で、7ビット表記だと「0110001」となります。
制御コードについては、以下をご参照ください。

「SP」や「NUL」、「CR」、「LF」など馴染みがあるかもしれません。ネットワークに詳しい人だと「ACK」や「NAK」、「SYN」なども馴染みがあるでしょう。
第三回の文字符号化方式で解説しますが、「SO」と「SI」も結構重要です。
ASCⅡがISO/IEC 646として国際規格化され、1967年に日本版ISO/IEC 646として作られた符号化文字集合が、JIS X 0201です。
ASCⅡとの違いは、ASCⅡの「\」(バックスラッシュ)が「¥」になり、「チルダ」が「オーバーライン」になりました。
JIS X 0201はこのASCⅡに相当する「ラテン文字集合」と片仮名を収録した「片仮名集合」の2つがあります。
以下はJIS X 0201の文字コード表です。


JIS X 0201のように日本以外の国でも、各国版ISO/IEC 646が作られました。
でもそれぞれの国のISO/IEC 646は混在して使用することができません。例えばASCⅡとドイツ語のISO/IEC 646を混在させることができません。そこで開発されたのが、ISO/IEC 2022という8ビットコードです。
ISO/IEC 2022は、複数の文字集合を混在することができるようになっただけでなく、複数バイトで 1 文字を表すことができるようにもなりました。
各バイトはISO/IEC 646と同じく制御コードのエリアを除く 94 文字分を利用できます。規格としては 3 バイト 1 文字でも 4 バイト 1 文字でも良いのですが、大部分は 2 バイト 1 文字の文字集合です。
それによって登場したのがJIS X 0208です。JIS X 0201では 94 文字しか収録できなかった文字が、JIS X 0208では 94 × 94 = 8,836 文字を収録することができるようになり、漢字を扱えるようになりました。
JIS X 0208では、1 バイト目を「区」と呼び、バイト目を「点」と呼びます。
以下は 16 区のコード表です。JIS X 0201と比較しやすいようにするため、通常とは縦横を逆にしています。
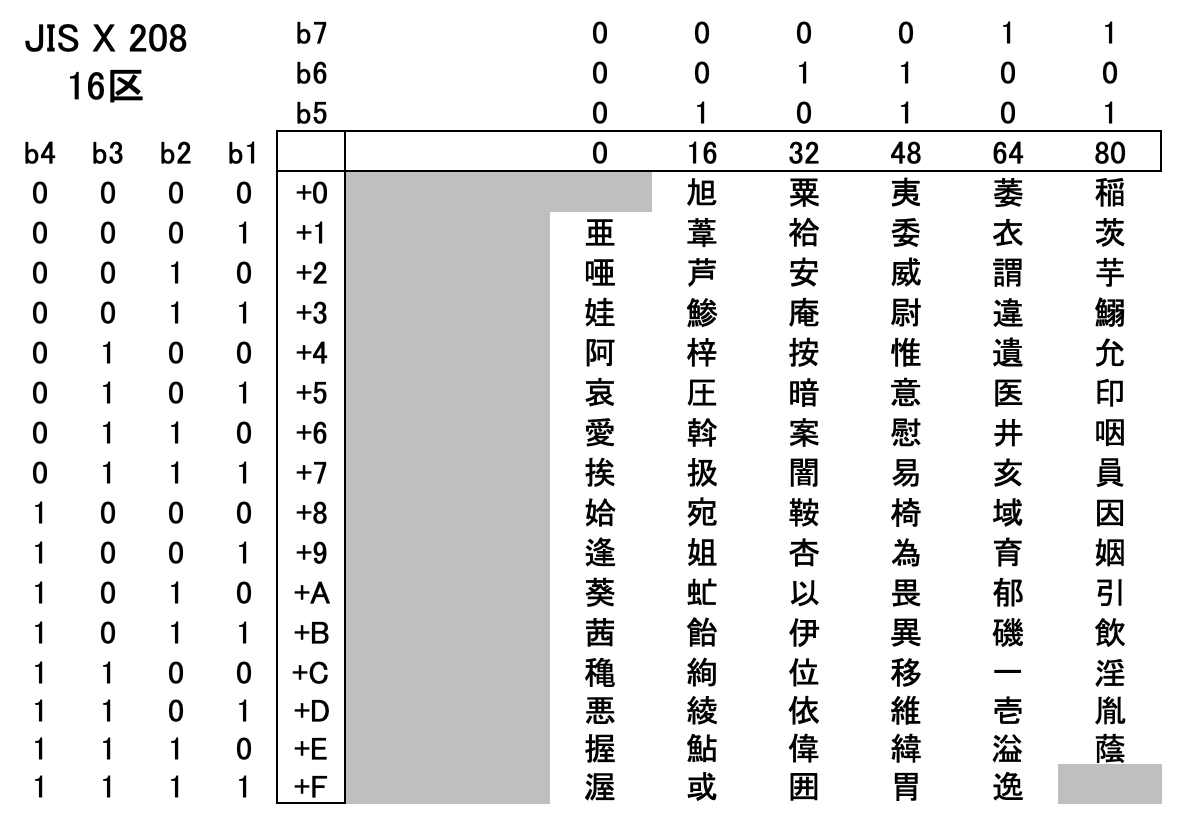
「安」であれば 16-34(または 16区 34点)、「井」であれば 16-70(または 16区 70点) と呼びます。
このJIS X 0208には、JIS X 0201に収録されている数字や英字、記号も収録されています。例えば 3 区のコード表は以下になります。

この「1」や「A」は、JIS X 0201とコードが異なるため、別文字として扱われます。この 2 つを区別するため、JIS X 0201の「1」や「A」を「半角」、JIS X 0208(JIS X 0213)の「1」や「A」を「全角」と呼ぶようになりました。
この「半角」や「全角」は、文字サイズを規定しているわけではなく、コードの違いを区別しているに過ぎませんが、見た目で区別できるようにするため、サイズの異なるフォントを使用するようになりました。
JIS X 0208にはJIS第1水準漢字とJIS第2水準漢字が収録されていますが、
(正確には、JIS X 0208に収録されている文字で使用頻度が高いものをJIS第1水準漢字、第2水準漢字と呼ぶようになりました)
より多くの漢字を使用したいというニーズが高まり登場したのがJIS X 0213です。
JIS X 0213にはJIS第3水準漢字とJIS第4水準漢字が含まれ、JIS X 0208には 6,879 文字が収録されていますが、JIS X 0213には 11,233 文字が収録されています。
JIS X 0208は、最大で 94 × 94 = 8,836 文字しか収録できませんでしたが、JIS X 0213はこれを2つ持つようにした文字集合となり、最大で 8,836 + 8,836 = 17,672 文字を収録することができます。
JIS X 0213の2つの文字集合のうちJIS X 0208の文字を収録している文字集合を 1 面、もう一つを 2 面と呼び、例えば「安」であれば 1-16-34(または 1面 16区 34点)のように呼びます。
6.Unicode
ISO/IEC 2022の登場で、大量の文字を収録できるようになりましたが、それでも全世界の文字を収録することはできません。
そこで登場したのが、Unicodeです。
ISO/IEC 2022は文字集合を切り替えることで、複数の文字集合を扱うことができるようになった規格ですが、一つの文字集合に全世界の文字を収録する規格がUnicodeです。
当初、このUnicodeは民間のコンピューター関連グループで開発されました。それと同時期に同じ思想で国際規格としてISO/IEC 10646(UCSとも呼びます)が登場しています。
全世界の文字を一つにするので、ISO/IEC 10646は 4 バイトで 1 文字の体系でしたが、Unicodeは似ている漢字(亞と亜など)を一つにすることで、2 バイト 1 文字の体系でした。
その後、ISO/IEC 10646とUnicodeが統合され、コード体系は 4 バイト 1 文字が採用されましたが、中身は旧Unicodeの 2 バイト 1 文字が採用され、上位2バイトは「00 00」固定となりました。
その後、2 バイト(16 ビット)で収録できる最大文字数 65,536 では不足することになり、21ビット(最大 2,097,152 文字)まで拡張され、現在では 143,859 文字が収録されています(2020年3月のバージョン13.0.0)。
ちなみにこのISO/IEC 10646は、JIS X 0221としてJISにもなっていますが、中身は全く同じものです。
Unicodeは、群、面、区、点で構成されています。
群は7ビット(16進で00から7Fまで)で128、面と区、点はそれぞれ8ビット(16進で00からFFまで)で256あります。これを全て使用すると 2 の 31 乗 = 2,147,483,648 という途方もない数の文字を収録することができます。
この群00、面00に、当初の 2バイト分の文字が収録されていて、基本他言語面(BMP)と呼ばれています。
現状のルールでは、群00、面0Fまでが使用可能となっています。
【振り返り】
第二回は、符号化文字集合でした。第三回は、文字符号化方式です。
第一回:概要
第二回:符号化文字集合
第三回:文字符号化方式(前編)
第四回:文字符号化方式(後編)
第五回:サロゲートペア
第六回:IVS
第七回:文字コードの歴史
第八回:文字化け