今日から入社する中途の後輩の面倒を見るため、しばらくオフィスに出社。
私の場合、入社して1年くらいは普通に出勤していたので、対面でいろいろな人に会うことができましたが、今はみんな在宅勤務なので私以外の人と対面で会う機会が少ないのがかわいそうです。
テレビ会議だと、どうしても顔をなかなか覚えられないので、自分が次に転職することがあったときに備えて、在宅勤務環境で彼女がどういうところで苦労するのか要注意です。
今日から入社する中途の後輩の面倒を見るため、しばらくオフィスに出社。
私の場合、入社して1年くらいは普通に出勤していたので、対面でいろいろな人に会うことができましたが、今はみんな在宅勤務なので私以外の人と対面で会う機会が少ないのがかわいそうです。
テレビ会議だと、どうしても顔をなかなか覚えられないので、自分が次に転職することがあったときに備えて、在宅勤務環境で彼女がどういうところで苦労するのか要注意です。
文字コードって、とっても難しいです。
そんな文字コードの中で、符号化文字集合について、可能な限りわかりやすく解説します。
1.符号化文字集合とは
「符号化文字集合」は、言葉どおり文字の集合です。ASCⅡやUnicode、JIS2004(JIS X 0213)などがこれにあたります。キャラクタセットとも呼びます。
例えば「1」という文字は、ASCⅡでは「31」、Unicodeでは「U+0031」になり、JIS2004には存在しません。「あ」という文字は、Unicodeでは「U+3042」、JIS2004では「2422」になり、ASCⅡには存在しません。
ASCⅡには制御コードを除いて 94 文字が収録されています。JIS2004には 11,234 文字、Unicodeには 143,859 文字(2020年3月の13.0.0バージョンの場合)が収録されています。
2.ASCⅡ
最初に作られた文字コードは、ASCⅡ(American Standard Code for Information Interchange)です。
1960年代に米国規格協会(ANSI)で定められました。ASCⅡは 7 ビットのコードで、2の 7 乗= 128 文字を表現できます。
そのうちの 34 文字は制御コードのため、実際に利用できる文字は 94 文字になります。この 94 という数字は、この後もたびたび登場します。
以下はASCⅡの文字コード表です。
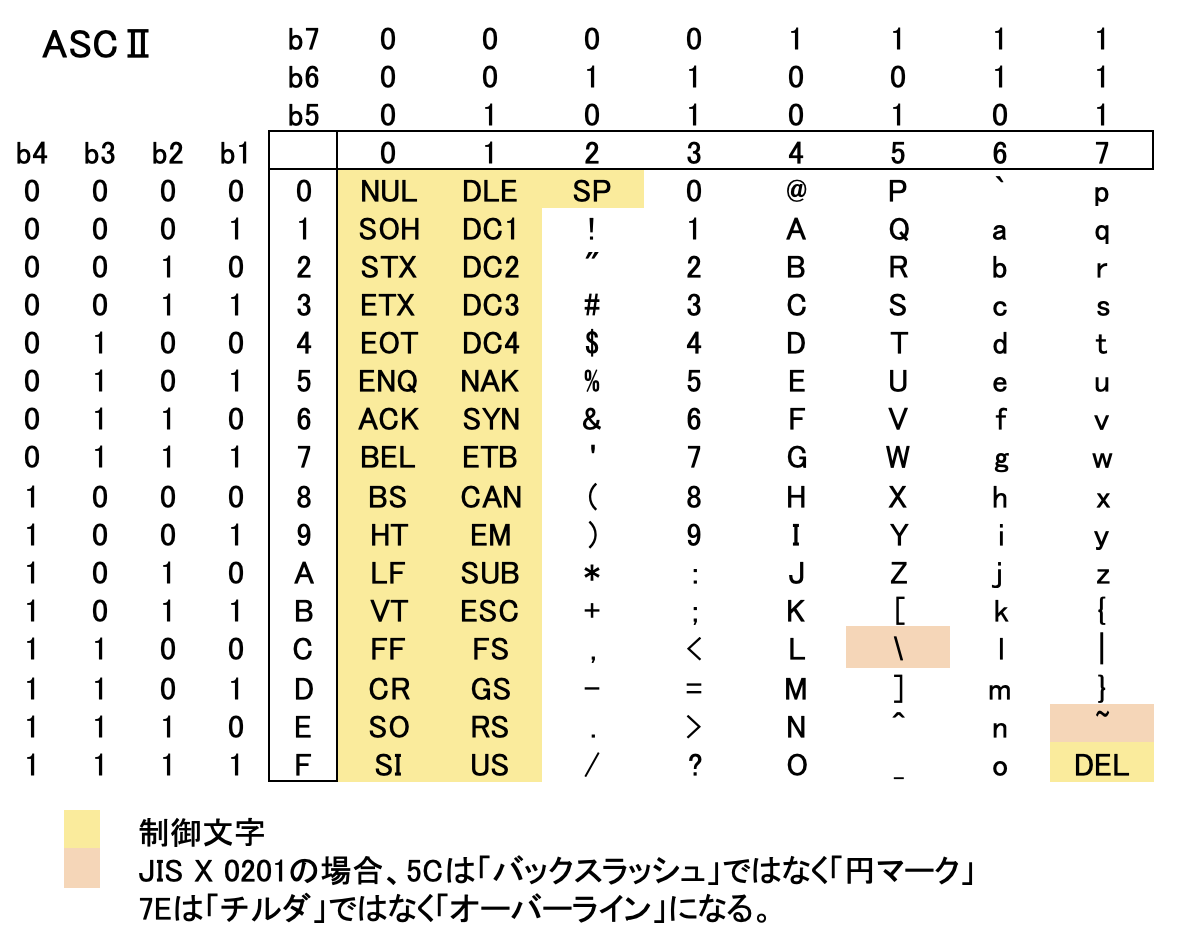
例えば「1」は16進表記で「31」で、7ビット表記だと「0110001」となります。
制御コードについては、以下をご参照ください。

「SP」や「NUL」、「CR」、「LF」など馴染みがあるかもしれません。ネットワークに詳しい人だと「ACK」や「NAK」、「SYN」なども馴染みがあるでしょう。
第三回の文字符号化方式で解説しますが、「SO」と「SI」も結構重要です。
ASCⅡがISO/IEC 646として国際規格化され、1967年に日本版ISO/IEC 646として作られた符号化文字集合が、JIS X 0201です。
ASCⅡとの違いは、ASCⅡの「\」(バックスラッシュ)が「¥」になり、「チルダ」が「オーバーライン」になりました。
JIS X 0201はこのASCⅡに相当する「ラテン文字集合」と片仮名を収録した「片仮名集合」の2つがあります。
以下はJIS X 0201の文字コード表です。


JIS X 0201のように日本以外の国でも、各国版ISO/IEC 646が作られました。
でもそれぞれの国のISO/IEC 646は混在して使用することができません。例えばASCⅡとドイツ語のISO/IEC 646を混在させることができません。そこで開発されたのが、ISO/IEC 2022という8ビットコードです。
ISO/IEC 2022は、複数の文字集合を混在することができるようになっただけでなく、複数バイトで 1 文字を表すことができるようにもなりました。
各バイトはISO/IEC 646と同じく制御コードのエリアを除く 94 文字分を利用できます。規格としては 3 バイト 1 文字でも 4 バイト 1 文字でも良いのですが、大部分は 2 バイト 1 文字の文字集合です。
それによって登場したのがJIS X 0208です。JIS X 0201では 94 文字しか収録できなかった文字が、JIS X 0208では 94 × 94 = 8,836 文字を収録することができるようになり、漢字を扱えるようになりました。
JIS X 0208では、1 バイト目を「区」と呼び、バイト目を「点」と呼びます。
以下は 16 区のコード表です。JIS X 0201と比較しやすいようにするため、通常とは縦横を逆にしています。
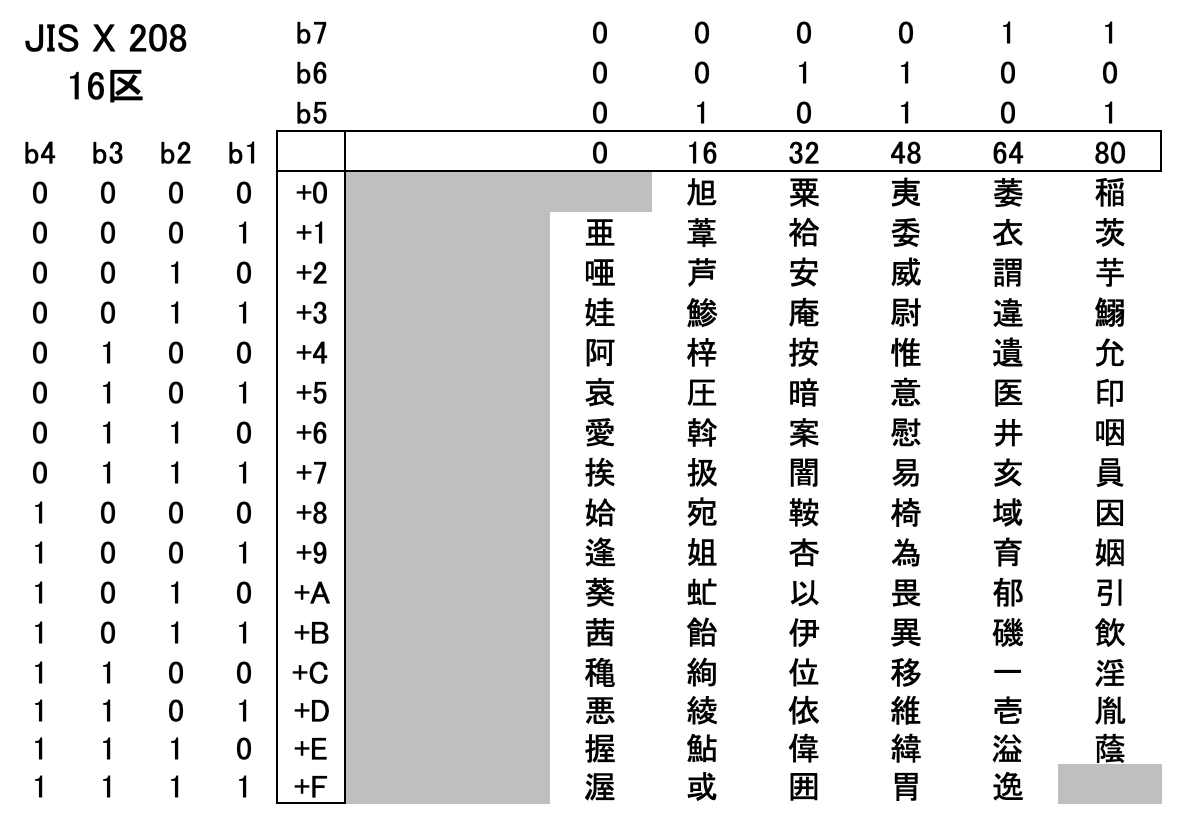
「安」であれば 16-34(または 16区 34点)、「井」であれば 16-70(または 16区 70点) と呼びます。
このJIS X 0208には、JIS X 0201に収録されている数字や英字、記号も収録されています。例えば 3 区のコード表は以下になります。

この「1」や「A」は、JIS X 0201とコードが異なるため、別文字として扱われます。この 2 つを区別するため、JIS X 0201の「1」や「A」を「半角」、JIS X 0208(JIS X 0213)の「1」や「A」を「全角」と呼ぶようになりました。
この「半角」や「全角」は、文字サイズを規定しているわけではなく、コードの違いを区別しているに過ぎませんが、見た目で区別できるようにするため、サイズの異なるフォントを使用するようになりました。
JIS X 0208にはJIS第1水準漢字とJIS第2水準漢字が収録されていますが、
(正確には、JIS X 0208に収録されている文字で使用頻度が高いものをJIS第1水準漢字、第2水準漢字と呼ぶようになりました)
より多くの漢字を使用したいというニーズが高まり登場したのがJIS X 0213です。
JIS X 0213にはJIS第3水準漢字とJIS第4水準漢字が含まれ、JIS X 0208には 6,879 文字が収録されていますが、JIS X 0213には 11,233 文字が収録されています。
JIS X 0208は、最大で 94 × 94 = 8,836 文字しか収録できませんでしたが、JIS X 0213はこれを2つ持つようにした文字集合となり、最大で 8,836 + 8,836 = 17,672 文字を収録することができます。
JIS X 0213の2つの文字集合のうちJIS X 0208の文字を収録している文字集合を 1 面、もう一つを 2 面と呼び、例えば「安」であれば 1-16-34(または 1面 16区 34点)のように呼びます。
6.Unicode
ISO/IEC 2022の登場で、大量の文字を収録できるようになりましたが、それでも全世界の文字を収録することはできません。
そこで登場したのが、Unicodeです。
ISO/IEC 2022は文字集合を切り替えることで、複数の文字集合を扱うことができるようになった規格ですが、一つの文字集合に全世界の文字を収録する規格がUnicodeです。
当初、このUnicodeは民間のコンピューター関連グループで開発されました。それと同時期に同じ思想で国際規格としてISO/IEC 10646(UCSとも呼びます)が登場しています。
全世界の文字を一つにするので、ISO/IEC 10646は 4 バイトで 1 文字の体系でしたが、Unicodeは似ている漢字(亞と亜など)を一つにすることで、2 バイト 1 文字の体系でした。
その後、ISO/IEC 10646とUnicodeが統合され、コード体系は 4 バイト 1 文字が採用されましたが、中身は旧Unicodeの 2 バイト 1 文字が採用され、上位2バイトは「00 00」固定となりました。
その後、2 バイト(16 ビット)で収録できる最大文字数 65,536 では不足することになり、21ビット(最大 2,097,152 文字)まで拡張され、現在では 143,859 文字が収録されています(2020年3月のバージョン13.0.0)。
ちなみにこのISO/IEC 10646は、JIS X 0221としてJISにもなっていますが、中身は全く同じものです。
Unicodeは、群、面、区、点で構成されています。
群は7ビット(16進で00から7Fまで)で128、面と区、点はそれぞれ8ビット(16進で00からFFまで)で256あります。これを全て使用すると 2 の 31 乗 = 2,147,483,648 という途方もない数の文字を収録することができます。
この群00、面00に、当初の 2バイト分の文字が収録されていて、基本他言語面(BMP)と呼ばれています。
現状のルールでは、群00、面0Fまでが使用可能となっています。
【振り返り】
第二回は、符号化文字集合でした。第三回は、文字符号化方式です。
第一回:概要
第二回:符号化文字集合
第三回:文字符号化方式(前編)
第四回:文字符号化方式(後編)
第五回:サロゲートペア
第六回:IVS
第七回:文字コードの歴史
第八回:文字化け
ワガママというか、ゴーイングマイウェイというか・・・
プライベートでも仕事でも、自分が嫌なことはやらない性格なので、やる気が出ないという状態がほとんどありません。
自分がやりたいことだけをやって来れたのも、若いころは自分の実力だと思っていましたが、40代になって「周りの人たちに恵まれていた」、この一言に尽きるのだなあとしみじみ思います。
特に会社の同僚たちは、嫌なことを一切やらない私を見て、やれやれと思いながらも温かくフォローしてくれていたのだと、ようやく最近になって気づくことができました。
それに甘えさせていただいて、これからも嫌なことは一切やらない自分でありたいと思います。

文字コードって、とっても難しいです。
そんな文字コードを可能な限りわかりやすく解説します。
1.文字コードって何?
情報システムで扱う「文字」は、「符号化文字集合(キャラクタセット)」「文字符号化方式(エンコーディング)」「フォント」の3つで構成されます。
「符号化文字集合」は、言葉どおり文字の集合です。ASCⅡやUnicode、JIS2004(JIS X 0213)などがこれにあたります。
「文字符号化方式」は、コンピューターで符号化文字集合を扱うためのコード化のルールです。UTF-8やShift-JIS、EUC-JPなどがこれにあたります。
「フォント」は、一番馴染みがあると思いますが、明朝体やゴシック体、Arialなどがこれにあたります。

2.符号化文字集合
最初に作られた文字コードは、ASCⅡです。
1960年代にアメリカの規格として作られました。ASCⅡは7ビットのコードで、2の7乗=128文字を表現できます。
このASCⅡをもとにして日本用に作られた符号化文字集合が、JIS X 0201です。ASCⅡとの違いは、ASCⅡの「\」(バックスラッシュ)が「¥」になり、「チルダ」が「オーバーライン」になりました。
その後、8ビット2つで1文字を表現する2バイトコードが誕生します。
JIS X 0208が日本語版の2バイト文字集合です。最大で8,836の文字を表現でき、常用漢字が1,945文字なので、かなり大量の文字を表現できることになります。
このJIS X 0208の対象になっている文字は、いわゆるJISの第一水準、第二水準と呼ばれる文字で、1997年版のJIS X 0208では6,879文字が収録されています。
その後、JISの第三水準、第四水準の文字を取り込むことになりますが、JIS X 0208の最大文字数8,836では足りなくなり、JIS X 0213が誕生し今に至ります。JIS X 0213では、11,233文字が収録されています。
ここでちょっと問題が出ます。このJIS X 0208やJIS X 0213には、JIS X 0201に収録されている文字が含まれていません。乱暴に言うと、JIS X 0201は半角文字、JIS X 0208やJIS X 0213は全角文字です。
そのため半角と全角で、使用する符号化文字集合を切り替えなければいけないという、ちょっと面倒なことが生じていました。
そこで誕生したのがUnicodeです。Unicodeは半角と全角の両方を収録しているだけでなく、世界中の文字を収録しています。Unicodeは可変長の文字コードですが、現在のUnicodeは最大で21ビット=2,097,152文字まで収録することができます。
3.文字符号化方式
符号化文字集合は、そのままだとコンピューターで扱うことが困難です。
例えば半角はJIS X 0201、全角はJIS X 0208を使用しようと思うとき、「1円」を文字コードで表すと、「1」はJIS X 0201で「31」、「円」はJIS X 0208で「315F」です。これを繋げると「31315F」となります。
ここで「3131」はJIS X 0208で「臼」、「5F」はJIS X 0201で「_」となるため、「11_」の文字コードは「31315F」、「臼_」の文字コードは「31315F」で、「31315F」の文字コードは「1円」でもあり、「11_」でもあり、「臼_」でもあるという状態になってしまいます。
この問題を解決するのが、文字符号化方式です。
符号化文字集合をコンピューターで扱いやすいコードに変換することで、文字を一意に表現することができるようになります。
代表的なものでは、ASCⅡとJIS X 0208を同時に利用できるようにしたものがEUC-JPで、Unix系のOSで利用されています。
JIS X 0201とJIS X 0208を同時に利用できるようにしたものはWindowsで有名なShift-JISです。
Unicodeはちょっと特殊で、単一の符号化文字集合で全ての文字を表現できるので、他の符号化文字集合との組み合わせは必要ありません。
ただUnicodeは可変長のため、コンピュータで扱いやすい固定長のコードに変換する方式が登場しました。
UTF-16は、Unicodeを16ビット(2バイト)の固定長コードに変換したもので、JavaやC#などの文字列処理で利用されています。
UTF-8は、UnicodeをASCⅡと互換性のある最大48ビット(6バイト)の可変長コードに変換したもので、ASCⅡと互換性があることからLinuxやWebブラウザー、Pythonなど広く利用されています。
4.フォント
ここでは、「字種」「字体」「字形」「書体」を区別せず「フォント」と呼びますが、これらは厳密には異なります。
「字種」は、文字の概念です。符号化文字集合に相当します。
「字体」は、文字の骨組みです。「亀」という字を100人の人が手書きすると、100とおりの「亀」になりますが、でも「亀」と認識できます。この「亀」と認識できる部分が字体です。
「字形」は、この字体を目で見えるようにしたものです。100とおりの「亀」は、すべて「字形」が異なります。
「書体」は、この字形の概念(様式)を抜き出したもので、同じ様式で作られた文字の集まりです。ゴシック体や明朝体などが書体です。
「吉」と「𠮷」、「斉」と「斎」は、字種と書体は同じで、字体と字形が異なります。
「亀」と「亀」、「鶴」と「鶴」は、字種と字体は同じで、字形と書体が異なります。
「未」と「末」、「矢」と「失」は、書体は同じで、字種と字体、字形が異なります。
【振り返り】
第一回は、文字コードの概要でした。第二回は、符号化文字集合です。
第一回:概要
第二回:符号化文字集合
第三回:文字符号化方式(前編)
第四回:文字符号化方式(後編)
第五回:サロゲートペア
第六回:IVS
第七回:文字コードの歴史
第八回:文字化け
