文字コードって、とっても難しいです。
そんな文字コードの中で、サロゲートペアについて、可能な限りわかりやすく解説します。
1.サロゲートペアとは
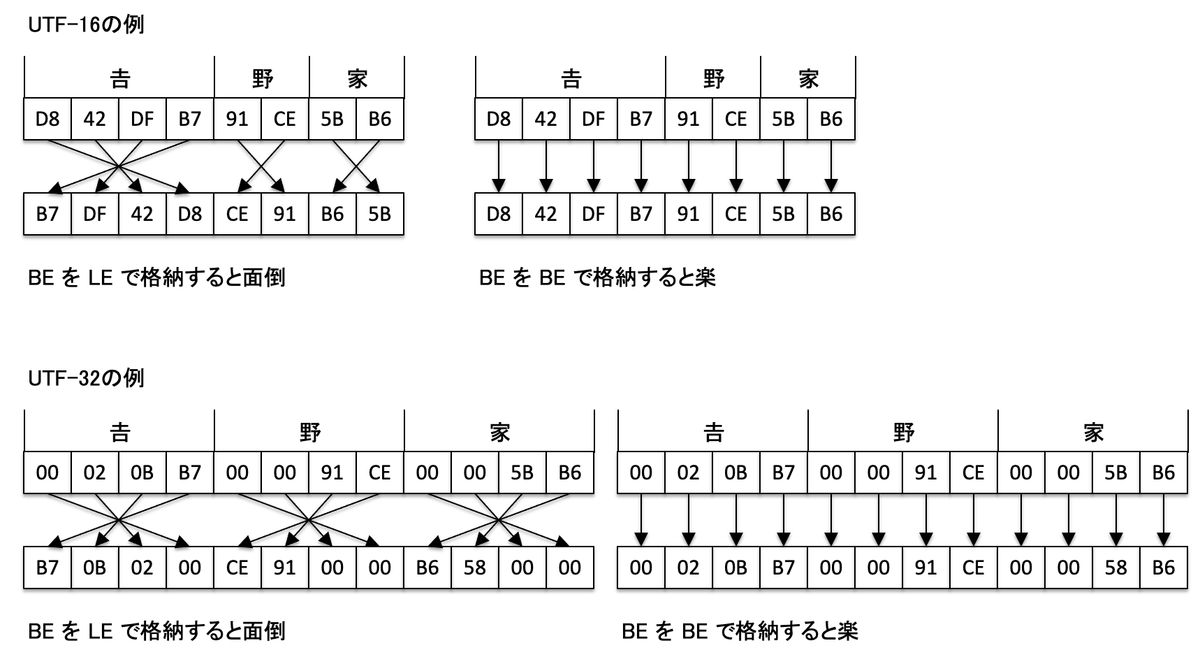
UTF-16 は基本は 2 バイトで 1 文字ですが、2 バイトで表せる文字は 256 × 256 = 65,536 と世界中の文字を収録するには不足するため、苦肉の策として 4 バイトで 1 文字を表すこととしました。
ただ全部の文字を 4 バイトにしてしまうと、それまで UTF-16 を利用していたシステムに大きな影響が出てしまうため、基本は 2 バイト 1 文字のままで、65,536 で収まらない文字だけ 4 バイト 1 文字としました。
この 4 バイト 1 文字で表される文字をサロゲートペアと呼びます。
古いプログラムでは、UTF-16 は 2 バイト固定の前提で処理をしているので、文字列操作でエラーが起きる可能性があり、注意が必要です。
ちなみに全部の文字を 4 バイト 1 文字にした文字コードは、UTF-32 です。
2.サロゲートペアの見分け方
サロゲートペアは 4 バイト 1 文字ですが、この 4 バイトは「 2 バイト」+「 2 バイト」で構成されています。
最初の「 2 バイト」を上位サロゲート、次の「 2 バイト」を下位サロゲートと呼びます。
上位サロゲートのコード範囲は D800 〜 DBFF で、下位サロゲートのコード範囲は DC00 〜 DFFF です。

このサロゲートペアで表せる文字数は 1,024 × 1,024 = 1,048,576 文字となり、現状の Unicode の最新バージョン 13.0.0 に収録されている文字数 143,859 文字を軽く上回ります。
3.サロゲートペアの作り方
Unicodeの U+0000 〜 U+FFFF までは、2 バイトで表すことができるので、U+10000 からがサロゲートペアとなります。
Unicodeは、理論上は最大 4 バイトですが、国際ルールで最大値が U+10FFFF(21ビット) と決まっています。
そのためサロゲートペアになる最大の文字数は、10FFFF − 10000 = FFFFF = 1,048,576 文字となり、ちょうど上位サロゲートと下位サロゲートで表せる文字数と一致します。(一致するように上位サロゲートと下位サロゲートを決めたというのが正確な言い方かもしれません)
そこでサロゲートペアが U+10000 から U+10FFFF の間にある前提で、Unicode の符号位置から 10000 を引き、その結果の 20 ビットの前半 10 ビットを以下のように上位サロゲートに、後半 10 ビットを下位サロゲートにマッピングすることで、サロゲートペアの文字コードが作られます。

例えば「𦥑」の Unicode は U+26951 です。ここから 10000 を引くと 16951 となり、これをビットで表すと 0001 0110 1001 0101 0001 となります。
この 20 ビットの前半 10 ビットを上位サロゲートにあてはめ 1101 1000 0101 1010( D8 5A )、後半10ビットを下位サロゲートにあてはめ 1101 1101 0101 0001( DD 51 )となります。


Unicodeは、群、面、区、点で構成されます。
このうち群 00、面 00 が当初の Unicode( 2 バイト文字)で BMP と呼ばれています。
2 バイトで収まらなかった文字(漢字)は、面 02 に収録され、それらが UTF-16 ではサロゲートペアとなります。

5.まとめ
UTF-16は 2 バイト文字なので、最大 65,536 文字を収録できますが、そのうち D800 〜 DFFF のエリア( 2,048 文字分)をサロゲートペア用に割り当てているため、 65,536 − 2,048 = 63,488 文字が2バイトで表すことができる最大の文字数となります。これにサロゲートペアの 1,048,576 文字を加えることで、UTF-16 で表せる文字数の最大は 1,112,064 文字となります。

【振り返り】
第五回は、サロゲートペアでした。第六回は、IVS です。
第一回:概要
第二回:符号化文字集合
第三回:文字符号化方式(前編)
第四回:文字符号化方式(後編)
第五回:サロゲートペア
第六回:IVS
第七回:文字コードの歴史
第八回:文字化け